Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
Metin ve sentaks analizi
corcam-dvr-kolay-kurulum
ES PROHLASENI O SHODE
Untitled
Ortaçağ Eğitim Kurumları Olarak Medrese ve Stadium
Alt üriner sistem semptomları ve erektil disfonksiyon
2013 / 2014 - SAYI: 25
w9. «Java - programowanie sieciowe
ANADOLU ÜNİVERSİTESİ
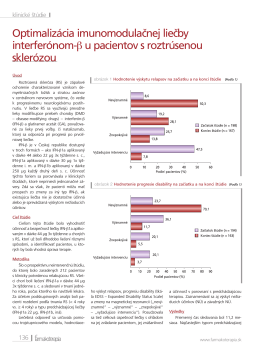
Optimalizácia imunomodulačnej liečby interferónom
Arapça II konu 8
Alt programların gerçeklenmesi
ÖZGEÇMİŞ - Tokat Teknopark A.Ş.