Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Krypto II - skripta-fmfi
Aplikovaná informatika – bakalárske štúdium (denná a externá forma)
Lorenzova šifra
Logické systémy doc. RNDr. Jana Galanová, PhD. RNDr
Slnko - Knihy Benjan
BEGA220A - SOS electronic
dizertačka (pdf)
Jste si jisti, že používáte PANTONE barvy správně?
PV062 – Organizácia súborov - Lekcia 1 – informačná teória
Radek Hnilica Radek Hnilica
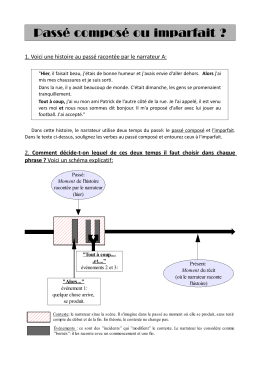
Passé composé ou imparfait ?
v katalógu vo formáte PDF
Temmuz 2015 - Mekatronik Mühendisliği
Instrukcja obsługi - Wagi elektroniczne
1-INF-115 Algebra 1
Informačná a sieťová bezpečnosť
Rozhodnutie 2011/130/EÚ, ktorým sa ustanovujú minimálne
Rokovací poriadok Akademického senátu FSV UCM
draft - Kedrigern
syntéza regulátora polohy pomocou zovšeobecnej metódy želanej
Dokumentácia k zadaniu na predmet Návrh prekladačov
Stromy
Rokovací poriadok dozornej rady