Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Úvod - Sorry
2. po - FORD Service
References
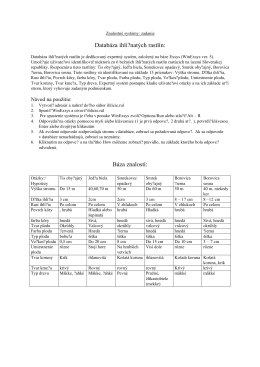
Databáza ihličnatých rastlín:
Bulletin Partisan de septembre 2016 ( PDF )
Domácí a kombinované kávovary - FORT
Kobanê halkının yanındayız!
Průvodce předmětem - Geomatika na ZČU v Plzni
Organizačný poriadok matematickej olympiády
Znalostní sy Znalostní systé Znalostní systémy Znalostní
Predviđanje maksimuma dnevne potrošnje električne
Adaptivní LMS systémy - Pedagogická fakulta
pub_rizikové chování(300).indd
Technický list
M stský elektrobus SOR EBN 8
ÚP Krahulov text
Jak vyhledávat v databázi léků
Fundamental and technical analysis of financial markets
Zamestnanecké cestovné výhody poskytované
Ontologie poza filozofią Studium metafilozoficzne