Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
110.94 KB - Akademik Bilişim Konferansları
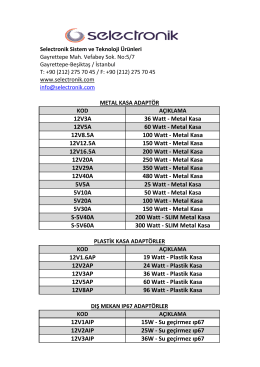
12V3A 36 Watt - Metal Kasa 12V5A 60 Watt
PA–025 Muscari muscarimi Türünün Antioksidant Aktivitesi ve
Zeytinyağı ve bitkisel yağ analizlerinde gaz
Sülfaklorpridazin-Trimetoprim Karışımının Broyler Dokularındaki
EK-11 Sonuç Raporu Formatı ANKARA ÜNİVERSİTESİ BİLİMSEL
Lamiaceae - Biyoloji Kongreleri
Akt305Odev1 Son Teslim Tarihi: 17 Ekim Perşembe
APLIKAČNÉ VYUŽITIE MATLAB-DDE KOMUNIKÁCIE S
biztonsági adatlap
Snímek 1 - RAFA 2015
Dr. Ezgi HACIKAMİLOĞLU
MART Ayı Yönetim Kurulu Faaliyet Raporu için TIKLAYINIZ.
Biyoyararlanım/Biyoeşdeğerlik Çalışmalarında Olası Hata ve
İçme Sularında Akrilamid LC/MS/MS Aplikasyonu pdf indir
immünosupresif ilaçların lc-ms/ms ile tam kan
BAZI UYGULAMA ÖRNEKLERİ
โสภารัตน ยุทธวรศิษย : การสกัดระดับจุลภาคในเ
GC-FID ile Bitkisel Sıvı Yağlarda Mineral Yağ Kalıntı
deney-4
ผศ.น.สพ.ดร.เดชฤทธิ์ นิลอุบล
Untitled - Yeojen Ozon Jeneratörü YEOJEN OZON
Akt305Odev1Cozum