Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Automatic knot adjustment using Artificial Immune
Yüz Kırıkları Cerrahisi Onam Formu (FR 119)
Shakespeare ve Goethe Felsefi Bir Bakış1
Sistem profila S 8000 IQ - Fenster Line PVC stolarija
sağlık bimleri fakültesi
Anadolu Mandalarında Süt Kompozisyonu, Rennet
2007-Free trim calculation using genetic algorithm
B-Spline Curve Approximation using Pareto
การแก ป ญหาเชิงชั้นหลายวัตถุประสงค โดยขั้น
Curve Fitting with NURBS using Simulated Annealing
Autonomous multi unmanned aerial vehicles path planning on 3
Minicanlı Dünyası, Ortak yaşam, Uyum ve Uyumsuzluklar
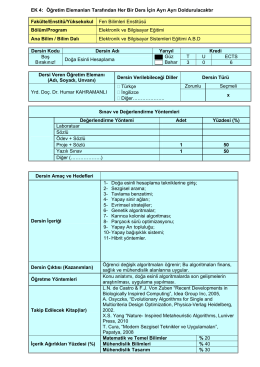
Doğa Esinli Hesaplama
Mustafa Barış Ata, M.D., M.Sc.
öz yeterlilik - Parantez Analiz Araştırma ve Danışmanlık
Clamart Infos - Octobre 2016
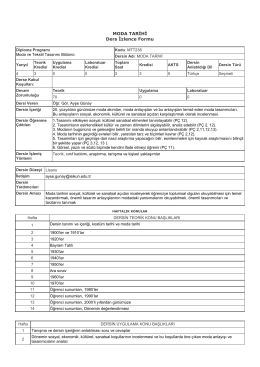
MTT 238
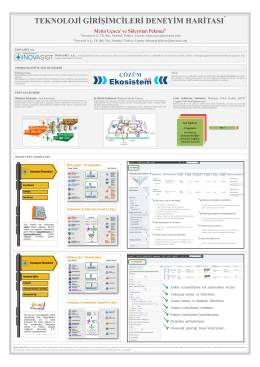
teknoloji girişimcileri deneyim haritası
QA – Assessment Danışmanlık Hizmetleri
Tersine Mühendislik Uygulamalarında Nokta Bulutu Verilerinden
Alias Ürünleri 2015 Broşürü
Boy-kilo ölçümü neticesinde BAŞARILI olan adayların 20 Nisan
ELTEL genel katalog