Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Reducing Instruction Issue Overheads in Application
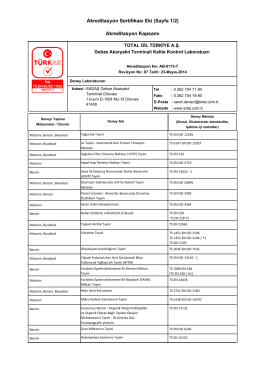
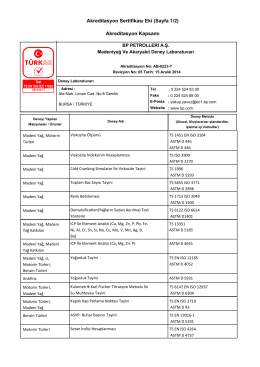
Akreditasyon Sertifikası Eki (Sayfa 1/2) Akreditasyon Kapsamı
Zestawy Arbonne Special Value Pack
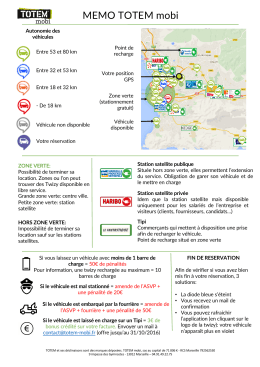
MEMO TOTEM mobi
Vous trouverez l`ordre du jours ici
Programı görmek için tıklayın
INSTRUCTION N° DSS/DGOS/CNAMTS/2016
ORIGINALNI NAUČNI RAD PRIMENA GENETSKOG
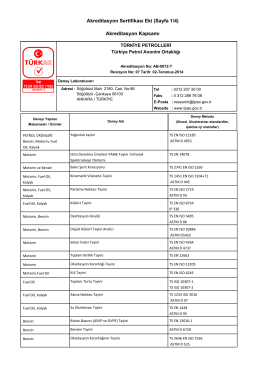
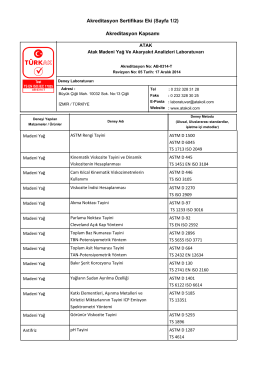
Akreditasyon Sertifikası Eki (Sayfa 1/4) Akreditasyon Kapsamı
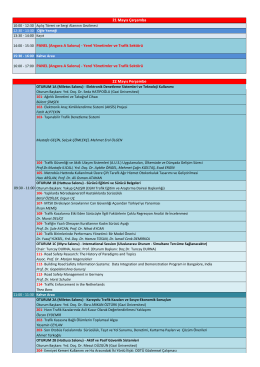
15:30 PANEL (Angora A Salonu)
kullanım kılavuzu
içindekiler 1 Güvenlik 2 Giriş 3 Mekanik tesisat 4
www.swiftturkiye.org
Zestawy Arbonne Special Value Pack
1) θıı çökeltisi için latis düzensizliği yaklaşık %15 dir. θıı 25 A
Akreditasyon Sertifikası Eki (Sayfa 1/2) Akreditasyon Kapsamı
Střední škola informatiky, elektrotechniky a řemesel Rožnov p. R.
Akreditasyon Sertifikası Eki (Sayfa 1/2) Akreditasyon Kapsamı
Critère de validation croisée pour le choix des modèles des petits
Menu - Skupa Café
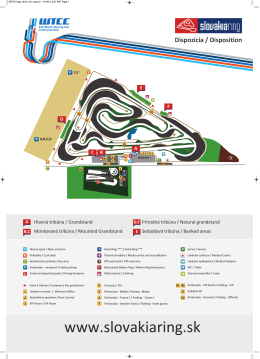
WTCC-mapa
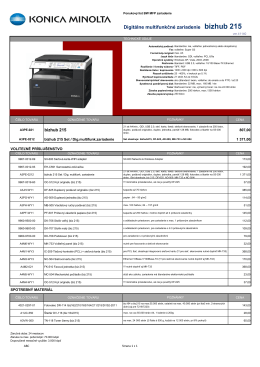
cenník
Modele Kartonowe