Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Nástroj pro optimalizaci fasetové navigace
ช คลังข้อมูลผู้เข้าชมงานแสดงสินค้าและเครื่อ
Jméno: Hana
Zhotovování stomatologických protéz 2013/2014
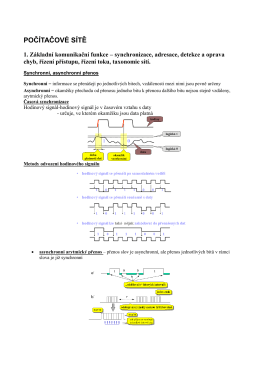
POČÍTAČOVÉ SÍTĚ
Egger (Superior) - dverepodlahybratislava.sk
Skiaskopie, skiagrafie - Nemocnice Strakonice
Magazín Komory zubních techniků ČR
Knihovní software Evergreen v České republice