Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Retrográdní slovníky
ASPEKTY TEÓRIE LEXIKÁLNEJ MOTIVÁCIE
český jazyk a literatura
Potrubí z tvárné litiny – tepelně izolované vedení Potrubie z tvárnej
Názvosloví ANORGANIKA.pdf
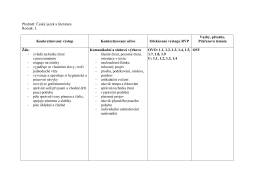
Předmět: Český jazyk a literatura Ročník: I. Konkretizovaný výstup
Otročiněves
J A Z Y K O V Ě D N É A K T U A L I T Y
Počítačová lingvistika Struktura jazyka Roviny analysy
Bulletin České společnosti pro ekologii
Generovany pdf soubor
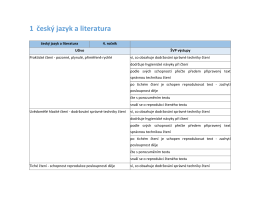
Tématický plán
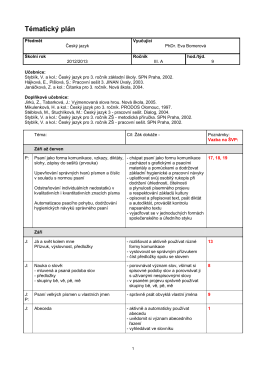
Tematický plán 3.ročník Český jazyk 2015/2016
miloslava sokolová, martin ološtiak, martina ivanová
Vážení rodiče, milé děti a sportovní přátelé
VNITŘNÍ SMĚRNICE OBCE RATIBOŘ č. 2 Evidence majetku a jeho
Obsah 7 - Polyglot
affidea presentation templates
Čeština neupadá. Upadáme my Lidové noviny
6 POVRCHOVÉ ÚPRAVY - DUKTUS litinové systémy sro
Číslovky
Latina
Psychologické následky dopravních nehod a péče o oběti