Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Zadání úlohy do projektu z předmětu IPP 2013/2014 XTD
Počítačová lingvistika Struktura jazyka Roviny analysy
vybrané vyhledávací funkce vybrané vyhledávací
Microsoft SQL Sever
Úvod do logiky (VL): 6. Vybrané tautologie
Úvod do logiky (VL): 10. Výrokově
V neděli 9. března jsme v Pinkasově synagoze v Praze uctili
INFORMACE PRO ROZHODČÍ ČVS - Utkání
Školní vzdělávací program pro gymnaziální vzdělávání
Jak tworzyć strategie przedsiębiorstw?
Gigaset C620
Projekt
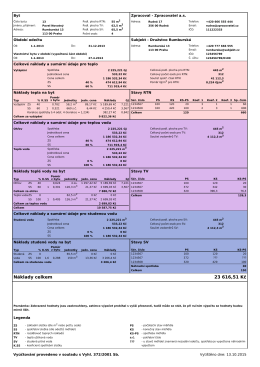
Náklady celkem 23 616,51 Kč
Způsoby šíření a využívání elektronických závěrečných prací a
Technické listy Flagstone (v novém okně)
Teorie jazyků a automatů Základy teoretické informatiky
SDD - Uputa za klijente pain.002
Gigaset E630
zpětné odkazy
SWB 2014 1. Vodopádový (analýza, návrh, implementace, testování
Dokumentácia k zadaniu na predmet Návrh prekladačov
schůze 23.11. - Krajský svaz stolního tenisu Olomouc
STKzap5_16