Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
Prvni setkani s TeXem
CUlogo - Petr Olšák
manuálu - Petr Olšák
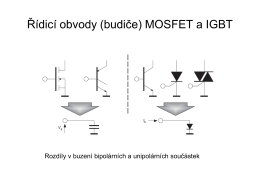
Řídicí obvody (budiče) MOSFET a IGBT
svi slajdovi u jednom pdf fajlu
OPmac – rozšiřující makra plainTEXu
Purchase Intention toward Safety Labeled Dairy Products in the
TeX pro pragmatiky
Coje sestava?
Tohle
Ako vytvoriť HTML newsletter?
CTUslides — jednoduché slídy ve stylu CTUstyle
v pozvánce