Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Lecture2
Orhan Bükülmez
Web Sitesi Yönetim Paneli
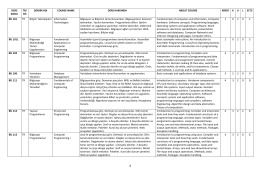
DERS KODU TR/ EN DERSİN ADI COURSE NAME DERS
Languages and Finite Automata
(API) İnşa Edin
CÜMLE ÇEŞİTLERİ
örnek sayfalar - Ezbersiz Matematik
01076203 digital circuit laboratory
String 13.1 String İşlemleri
Lecture3
Veri Tabanı Yönetim Sistemleri
iletşim kur 3 - Estetik İzler
Algoritma ve Akış Şeması Sunum
derleyici tasarımı ödev
Üslü Sayılar
Yetenek Sınavına Gireceklerin Aday Numaralarını Gösteren Liste
(Idiosyncrasie ) ve İkinci Dil Öğreniminde Dilden Dile Aktarım
örgütsel karar verme
Startlist - OKUL SPORLARI YÜZME MÜSABAKASI (YILDIZLAR
Anlamsal arama motoru
while (1)
yazının devamını okumak için tıklayın