Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
GÜRÜLTÜLÜ SES TANIMADA REGRESYON KULLANIMI Özet Bu
USE OF REGRESSION IN NOISY SPEECH RECOGNITION Abstract
Untitled - Dumlupınar Üniversitesi
หลักสูตรวิศวกรรมศาตรมหาบัณฑิต และ หลักสูตร
Sayın Acentemiz,
zajmovi - WordPress.com
Ses Komut Tanıma İle Gezgin Araç Kontrolü
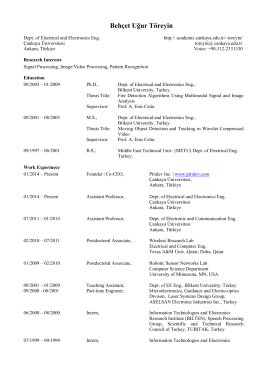
BEHÇET UĞUR TÖREYİN - Çankaya Üniversitesi
ir sensor data visualization
Vibrotest 60 - B & K sro, Bratislava
SBE_TEZ_YAZIM_KILAVUZU_v1
broşürü - TOK 2014 - Kocaeli Üniversitesi
FREQUENCY ANALYSIS OF SPEAKER
Teória - Elektrické pole a elektrický prúd
DEĞİŞEN VE GELİŞEN YAYINCILIK TEKNOLOJİSİ 50.YIL
Kapak - Osmangazi Üniversitesi İktisadi ve İdari Bilimler Fakültesi
altın bir rüya
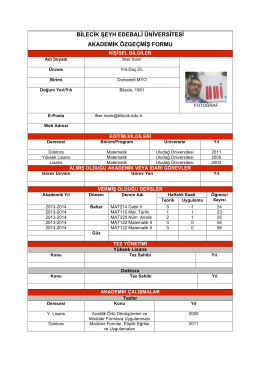
Yrd.Doç.Dr. İlker İNAM - Bilecik Şeyh Edebali Üniversitesi Matematik
Opis All Inclusive - Wezyr Holiday Service