Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
OLYMPIÁDA V INFORMATIKE
Poljoprivredna savetodavna i stručna služba Jagodina 7
NIKKISO Canned Motor Pumps
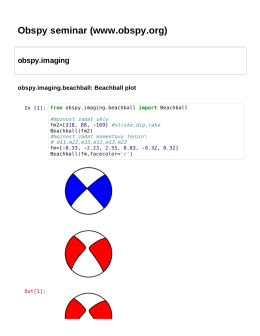
Obspy seminar (www.obspy.org)
null
Návrh a realizácia informačného systému správy
Ukážka z knihy [PDF 623.4 kB]
0 - JAZ sro
Október – mesiac modlitby posvätného ruženca
katalóg výstavy - Krajské osvetové stredisko v Nitre
Prehľad literatúry pre 1. a 2. ročník nové! - Zmaturuj.sk
Rozprávky z lesa
2/2012/2013 - na stiahnutie
MVC_redesign1-1
9. MET Ó DYPODROBN É HOMERANIA Podrobné meranie
Jesenné ráno (Umelecký opis) Zobúdzam sa do pestrofarebného
http://neuron.tuke.sk/~vrana/XML/ www.zvon.org XML copy editor 1
1. Co to jest monitor? Jest to zbiór procedur, zmiennych i
žiačik - Základná škola, Janigova 2, Košice
Grafové algoritmy
Telekomunikačné služby – súbor technických, prevádzkových a
letöltés
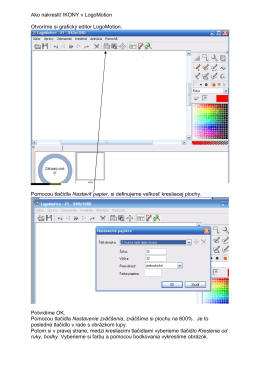
PL Logomotion



![Ukážka z knihy [PDF 623.4 kB]](http://s2.readgur.com/store/data/000214744_1-a03fc3316ef509c60dff126391e272e9-260x520.png)