Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
diplomová práce - Katedra hodnocení textilií
Terminológia v analytickej chémii - Department of Analytical Chemistry
zimowe - Koło Naukowe Matematyków UŚ
Orlik - Urząd Gminy Sadki
peter.csiba.proj3a
Použitý kuchynský olej sa nesmie vylievat do kanalizacie, ale vela
článok
Podklady pro cvičení VaKSD - Katedra částí a mechanismů strojů
Güç ve hareket iletimi - Prof.Dr Akgün Alsaran
Lisansüstü Çalışmalarda MATLAB
SINAV TARİHİ: 16.1.2016 SINAV ADI: Yeterlilik Sınavı II. Oturum
Studijní text [pdf] - Vysoká škola báňská
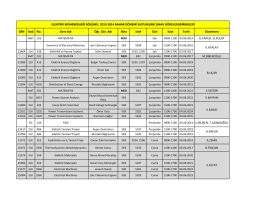
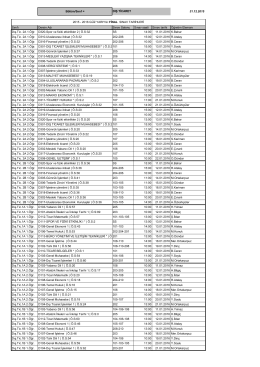
CRN Kod No. Ders Adı Öğr. Gör. Adı Bina Sınıf Gün Saat Tarih
talasasti filteri z-linija sa sistemom zamene / wave
Dış Ticaret
İMGE İŞLEME Ders-2
Praktikum za za laboratorijske vježb vježbe iz
Bélanger anglais 2016
Návod na váhu NT alebo NTS
Elektronický vaporizér EP601 - Návod na použitie
BETARD
PrintJet ADVANCED
analiza pracy modulatora wektorowego z trajektoriami








![Studijní text [pdf] - Vysoká škola báňská](http://s2.readgur.com/store/data/000160718_1-d95a5a9380a165cde53a83e470e059b8-260x520.png)