Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Poznámky k cvičeniu č. 3
笴" キ$%&`籔)*+,瞁.
NMO spektrum betegség – a neuritis retrobulbaris
Poznámky k cvičeniu č. 7
A neuroimmunológiai kórképeket (elő)jelző szemtünetekről
Pobierz pdf
Rozszerzony Skonsolidowany Raport Kwartalny za I
pdf pre tlač - Kabinet software a výuky informatiky
NAKUPOVAŤ U NÁS SA OPLATÍ! ZA KAŽDÝ
RILL - Politechnika Poznańska
KOMPARO
( ) ( ) { }v
Teorie jazyků a automatů Základy teoretické informatiky
Dokumentácia k zadaniu na predmet Návrh prekladačov
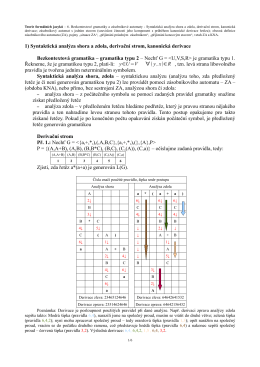
1) Syntaktická analýza shora a zdola, derivační strom, kanonická
SPRÁVA O NEHODE
Aktuálne informácie pre motoristov Úvod S účinnosťou od 1. júna
analiza skupień, algorytm k-średnich
Aplikácia matematiky v informatike - A-Math-Net
Tomáš Plachetka Fakulta matematiky, fyziky a informatiky
6. Mały ster
Počítačová lingvistika Struktura jazyka Roviny analysy
Domácí úkol č. 12