Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Riešenie problémov s ohraničeniami
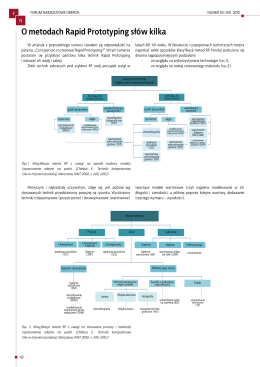
O metodach Rapid Prototyping słów kilka
Pokroky matematiky, fyziky a astronomie
Skrypt - fulmanski.pl
Aplikovaná informatika – bakalárske štúdium (denná a externá forma)
Cesty a tvorba Josefa Kelemena. Rozměr života
Základná príručka používateľa
Search List F - Skoumal Krisztián
Médio Mag #13 septembre octobre 2016 - SAINT
Mládež ako cieľová skupina pre rozvoj vidieka
Spravodajca SAIG 42/2011
Príkazy jazyka CPP
hygiena rastlinných tukov a olejov
double - Nechodím na Prednášky.sk
Strategii Rozwoju Polski Centralnej do roku 2020 z perspektywą 2030
Základná príručka používateľa
załącznik 2 tabele przejscia
vzor vo formáte pdf si stiahnete tu. - Enviros
Režeme na milimeter presne!
Skriptá
Otázky na
Novinárske príspevky stredoškolákov
null