Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
On the Possibilistic Approach to Linear Regression with Rounded or
Detaylı bilgi için tıklayınız.. - Yıldırım Beyazıt Üniversitesi
197 etkin, etkili ve uygulanabilir karar verme: etkileşimli bulanık
Úsměv v dešti OKAPOVÉ SYSTÉMY
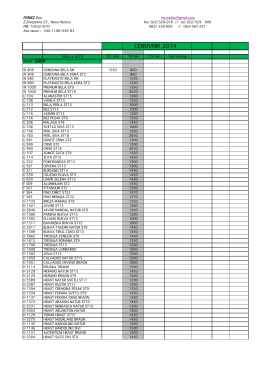
cenovnik ferrez - Skini slike samo kastamone.xlsx
PowerPoint Sunusu - Inet-tr
195.01 KB - Inet-tr
Calanques de la Côte Bleue - Site officiel de l`Office de tourisme de
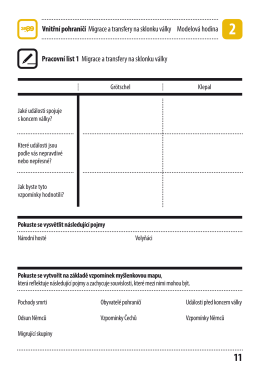
Pracovní list - Československo 38-89
Szarnyaskapunyito motor
เอกสารประกอบการบรรยาย
buji ateşlemeli motorlarda silindir içinde oluşan maksimum
Full Text - Z ITU Journal of Faculty of Architecture
18th CZECH-JAPAN SEMINAR
The Doctrine of Active Resistance in the Sixteenth Century