Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Incremental Clustering-Based Compression
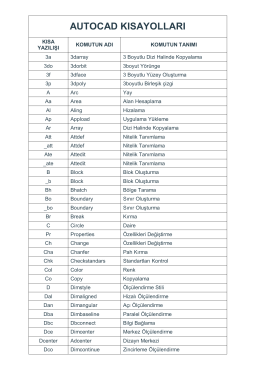
autocad kısayolları
pobierz w pdf
Abstrakt
wykaz czasowników
OGŁOSZENIE SPRZEDAŻY W FORMIE AUKCJI Bieszczadzki
Miloš Radovanović Curriculum Vitae
Wykład 3 Labview 2
Bölgesel Kalkınmada Kümelenme: Turizm Kümelenmesi
AutoCAD
VIRTUALIZACIJA ZA MALE I SREDNJE KOMPANIJE - RRC-u
Veri Şifreleme Teknolojileri
DEH-X5700BT DEH-4700BT
Agenty a doplňky produktu Symantec Backup Exec
Zeyilname 2 – 06.12.2014 (PDF)
Hf-3 Öğrenmede Multimedya İlkeleri
Microsoft Hyper-V vs VMware vSphere
Sunum dosyası - Gazi Üniversitesi
รัตนธ์พงค์ ใสแก้ว / นักวิชาการคอมพิวเตอร์