Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Statistická teorie rozhodování
Strukturální regresní modely
Pozvánka - Zeka plus, sro
Pozvánka ke zkoušce
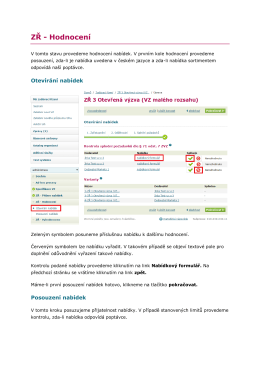
ZŘ - Hodnocení
EN 771-2 Vápenopískový zdicí prvek
Uveďte postačující předpoklady pro existenci a
Strojové učení
EN 771-2 Vápenopískový zdicí prvek
kategorie I SENDWIX 14DF–LD 1-2 prvek
Zplynovací KoTlE RoJEK KTp
15. Pravděpodobnost - úlohy k procvičení
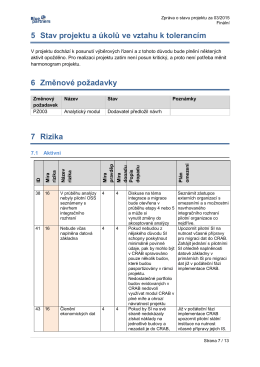
5 Stav projektu a úkolů ve vztahu k tolerancím 6
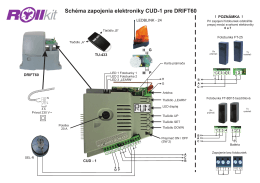
manual zmensený
Vzorová písemka je zde
3/2013 - magna energia
pozvánka - Singulární společnost Zádveřice
008/2012 - Múzeum v Kežmarku
reseni
Shrnutí
Palačinky, sladké i slané 1 litr mléka, 2 až 4 vejce, špetka soli, 40
Teoretické otÃÂ