Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
brno university of technology traffic analysis from video
Ku_wspolnocie_2_2015 - Parafia św. Józefa w Lublinie
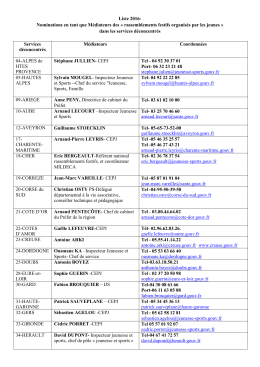
Liste 2016 - Jeunes.gouv.fr
E-Dergiyi İndirmek İçin Tıklayınız.
ÖZGEÇMĐŞ - İstanbul Teknik Üniversitesi
Human Detection in Forestal Area Videos
AUTYZM
บทความของวิทยากร - The Virology Association (Thailand)
Blu-ray™ Disc Player - CNET Content Solutions
Umění číst stále žije
Nástroje a techniky zpětné vazby marketingových výstupů
Orava je krásny k
Here
kliknite ovde
“GÜNEŞ ENERJİSİ ve UYGULAMALARI” DERS NOTLARI
Makine Öğrenmesi İle Ürün Sınıflandırma İncelemesi
Socijalna pomoć ne smanjuje siromaštvo
3 - Portal
rychle naskočte do rozjetého vlaku
PRVKY BETONOVÝCH KONSTRUKCÍ
KLAS JE naših ra vni 1-4, 20 1 4. ČASOPIS ZA