Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
01/2013 - Acta Informatica Pragensia
Noterlik Bilgi Sisteminin Sahiplik ve Kullanım Hakları ile Şekline
ve zdravotnictví
Počítač HP ProDesk 490 G1.pdf
Principy signalizace SIP - Teorie a praxe telefonie
01/2014 - Acta Informatica Pragensia
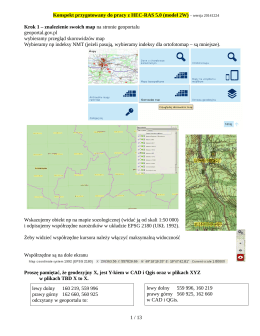
Konspekt przygotowany do pracy z HEC
การตรวจหาการโจมตีแบบ DoS ร วมกับฮันนี่พอทบนเครือข าย
prelom 2008 II.qxp
Zaštita podataka u bežičnim WLAN i WAN računarskim
Deník - OFS Třebíč
Stáhnout PDF
İçerik için tıklayınız
Produktový list v českém jazyce
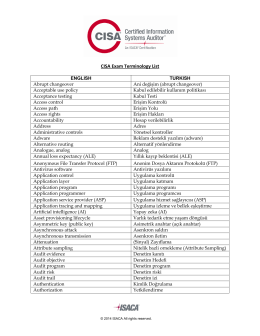
ISA-Exam-Terminology-List_xpr_Tur_1114
Program - Most k partnerství
Baktérium térkép az infekciókontroll tevékenység szolgálatában
Stav řešení Enterprise Architektury
Výberové konanie - profesor, docent na FEI TUKE
Možnosti modifikácie vlastností vybraných feromagnetických
121 - Telekom
Oznámenie o konaní obhajoby dizertačnej práce
Informacja Zarządu RSM - Radomska Spółdzielnia Mieszkaniowa