Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
číslo 7 - Slovenská štatistická a demografická spoločnosť
CONTACTS R OUND THE WORLD - JAMI Electronic Slovakia, sro
cz - O SMT-info
Zpravodaj pro rodiče 2015
acrobat - Notárska komora Slovenskej republiky
Ročník 23, číslo 3, září 2012 - Česká statistická společnost
ISSN 1336-7420 - Slovenská štatistická a demografická spoločnosť
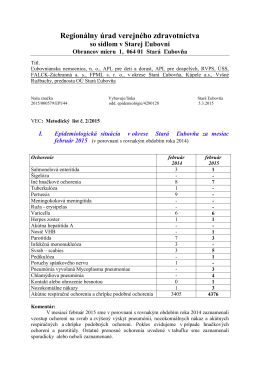
Regionálny úrad verejného zdravotníctva so sídlom v Starej
Sborníku abstrakt z 5. Odborné konference KZ ZZS ČR 2013
Risk Measures in Non-life Insurance Company Miery rizika v
číslo 7 - Slovenská štatistická a demografická spoločnosť
číslo 7 - Slovenská štatistická a demografická spoločnosť
Agilné metodológie riadenia vývoja softwaru
analýza samovražednosti na slovensku av českej republike
20 let samostatnosti z pohledu demografie čr, sr, čsr 20 rokov