Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
Sborník příspěvků
Nowości w protokole BGP Optymalizacja routingu
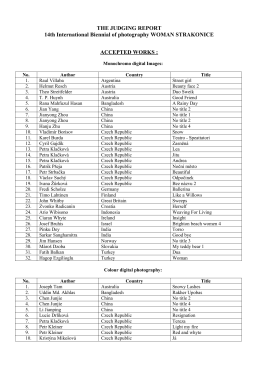
Acceptance and Award list of 14th International Biennial
85. szám - Full Circle Magazin
Program - Europen
katılımcı belgesi - Gömülü Linux Sistemleri
Uwagi do wydania, do dystrybucji Debian 7.0 (wheezy), System z
Opracowanie: Piotr Kania Stron a
komix letak advanta komunikacni platforma v3.indd
Veřejný cloud na open- source platformě OpenStack
Multiboot PKT/BMT 4.11 - opis przypadku
FreeIPA a SSSD - Pokročilá správa uživatelů v Linuxu
Program - EurOpen