Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
PostgreSQL ve verzi 9.2, 9.3 a 9.4 SQL
ภาษาซี
laboratorium iv
generácie patríte? generácie patríte?
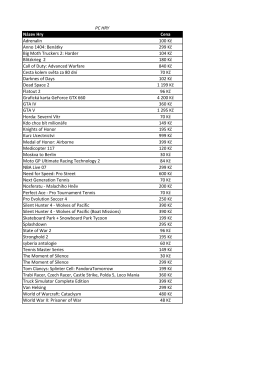
seznam her ke stažení v pdf
Joomla! mint keretrendszer
BIURO PROJEKTУW „Proj
Nestrukturovaná a senzorová data
PostgreSQL návrh a implementace náročných databázových aplikací
Backup eXpert for QNAP Backup i synchronizacja w jednej aplikacji
Práca s databázou a SQL
Návod na obsluhu přenosného hasicího přístroje - bezpo
ostravská univerzita v ostravě
PROGRAMOVÁNÍ V SQL
2. Türkiye PostgreSQL Konferansı Programı 1. Salon (B Blok İletişim
vt2014-1 Lab Dok. 6. Hafta.
Kamu SM
Veri Tabanı Yönetim Sistemleri
NP-úplné a NP-těžké úlohy, Cookeova věta, heuristiky na - OI-Wiki
Monitorowanie działania vacuum i autovacuum
XML databázy
Wiecej Informacji
Bi-Direction Replication