Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Diplomova Prace - Bc. Tomas Vogeltanz
Srpen 2015 číslo 54 BORS Břeclav a.s. MIMOŘÁDNÉ VYDÁNÍ Od
Dijital arşiv otomasyonu
Dengesiz deney düzenlerinde sağlam test
VŠB - Technická univerzita Ostrava
Pobierz ulotkę informacyjną
Humanita - Slovenská humanitná rada
Mity i realia OZEkoncowy
2 Stisknutím
openMagazin 6/2011 v PDF
PRAKTICKÉ UKÁZKY V QUANTUM GIS
Proracun puznog reduktora.pdf
book2net flaş
grafika na stronie www
Počítačová grafika a grafická informácia
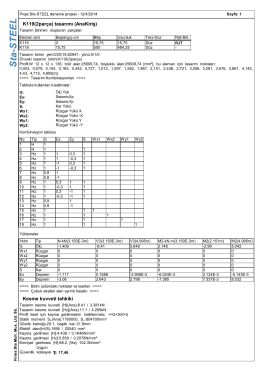
K119(2parça) tasarımı (AnaKiriş) Kesme kuvveti tahkiki
Optimální formát pro archivaci a zpřístupnění
FGK (Dvorak)
Příručka pro tisk fotografií
KLASIFIKACE OBJEKT V OBRAZU A VYU ITÍ SYSTÉMU
I. uzávěrka - Mezinárodní výstava Praha
Technické informace - Plynové kondenzační kotle BRÖTJE
8 bit