Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
ostravská univerzita v ostravě
Filmsk na stiahnutie vo formáte PDF
prezentácie
Sborník konference - Most k partnerství
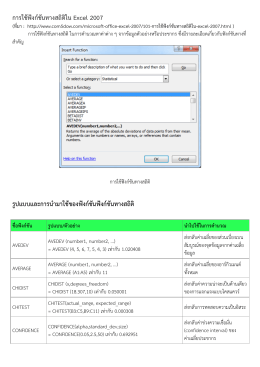
การใช้ฟังก์ชันทางสถิติใน Excel 2007 รูปแบบและการนา
Dodatok 23-2013 k zmluve 84-2012-OZIŠ.pdf
cały numer pisma "Uczę Nowocześnie"
Faruk Çubukçu Bilgi Teknolojileri Danışmanlık Şirketi
Základy biostatistiky s využitím Excelu - pokrok
Tam Metin İndir - E-Journal of New World Sciences Academy
Český návod (PDF)
DOGANAY katalog 2014bazalt1
DataPro E-shop - efektivní způsob prodeje na Internetu
Podrobný popis funkcí
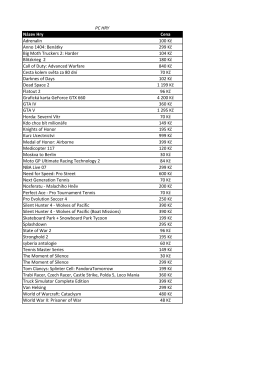
seznam her ke stažení v pdf
พฤติกรรมเชิงสุ่มของหลักทรัพย์ - คณะพาณิชยศาสตร์และการบัญชี
Ročník 23, číslo 3, září 2012 - Česká statistická společnost
Junák – organizace a vnitrní predpisy
null
215.1.5 STANOVENÍ VODY V ROPĚ
znalecký posudek - Exekutorský úřad Písek / JUDr. Stanislav Pazderka