Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
LETNÍ DOKTORANDSKÉ DNY 2012 - SAMI
Představení společnosti
Klasifikácia život ohrozujúcich stavov
D14. Viskoelasticita. Maxwellov model. Kelvinov (Voigtov)
CENÍK 2014 - ForFuture
Fonologický lexikální korpus češtiny a jeho analýza1 Aleš Bičan
Demir Miktarının Redoks Reaksiyonu ile Belirlenmesi
Diplomová práce - Vysoké učení technické v Brně
Obvodová řešení rezonančních měničů
III. LETNÍ DOKTORANDSKÉ DNY 2013 - SAMI
Október/Říjen 2013
Cenník LG a CARRIER
MATEMATİK MUHAMMET AŞKIN TÜRKOĞLU TOPLAMA PRENSİBİ
Statistická teorie rozhodování
1. ORGANIZÁCIA 2. HLAVNÉ ÚLOHY A ROZPRACOVANIE CIEĽOV
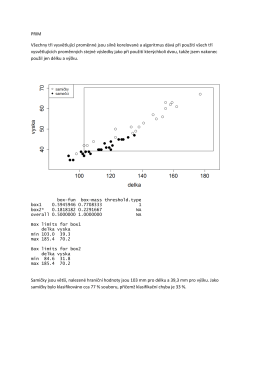
PRIM Všechny tři vysvětlující proměnné jsou silně