Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
kryptografie.pdf
Geometrické praktikum
MATURITNÍ ZPRAVODAJ
Kódovanie prenosu I.
perspektivní komunikace 21. století - SŠIEŘ
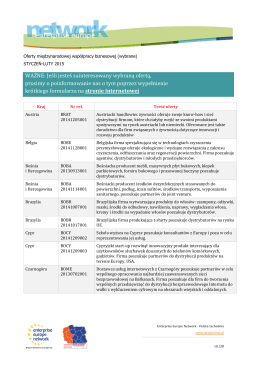
WAŻNE: Jeśli jesteś zainteresowany wybraną ofertą, prosimy o
02 sul nad zlato.pdf
VKO - Větrání kotelen - PDF
Analýza potřeb dětí a mládeže ve městě Litoměřice
POKYNY PRO PSANÍ DIPLOMOVÉ PRÁCE
formát PDF - sylaby a elektronické učebnice
Pocitacova grafika
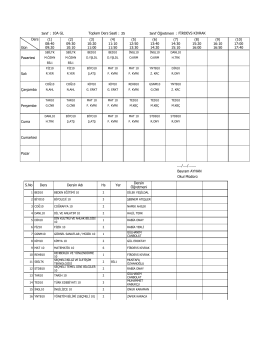
Sınıf : 10A GL Toplam Ders Saati : 35 Sınıf Öğretmeni : FİRDEVS
FGK (Dvorak)
2.3. Rovnice a nerovnice s absolutní hodnotou
50. Které protokoly popisují standardy IEEE 802.11, IEEE
Nejkratší cesty
Odložené věci dostanou druhou šanci
Maturitní zpravodaj 35
ReDat News I/2015
Co je nového v GL 2015
Ukázka - Rubico
INFORMATIKA Teorie informace - matematika–fyzika–informatika