Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Cvičení ze statistiky
Cvičení ze statistiky
Statistika
Statistika a pravdepodobnost / Dagmar Blatna
Gaussovo rozdělení
Ročník 25, číslo 3, září 2014 - Česká statistická společnost
NEPARAMETRICKÉ METODY
Jozef Chajdiak - STATIS Bratislava
POZVÁNKA - Institut geoinformatiky
21.4.2015 Svitavský deník Hosté byli výborní, chválí si show
tradiční bednářství Josef Hrůza
Informace o zápočtu a zkoušce, ukázkové
Odborný posudek vedoucího diplomové práce
Matematika III - v příkladech 08
ROZKLAD ROZPTYLU
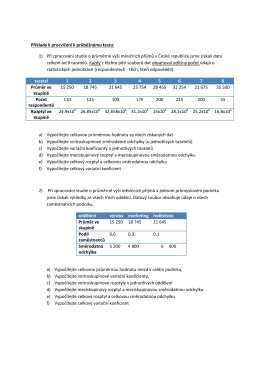
Příklady k procvičení k průběžnému testu: 1) Při zpracování studie o
Měření ozubených kol rozměr přes zuby
Pomůcka pro zjištění rychlosti lokomotivních vlaků po výpočtu
Text zadání
null
1. Rozdělení náhodné veličiny
Územní rozhodnutí o umístění stavby
Pracovn list 24 - Vpoty cestovnch nhrad