Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
MECH Lenka Lhotská, Miroslav Burša, Michal Huptych
CESSNA 150 NORMAL PROCEDURES
MEFANETin 2014/01
Certyfikat Rejestracji - Hospicjum św. Łazarza w Krakowie
Total Kalça Protezi Yapılan Yaşlı Hastalarda Tek Taraflı Spinal
Nečtiny 2014 - Život je boj - plakát - facelift-jmena
II 2013
print - Averia
2. číslo časopisu BOOM
Povídky
École de technologie supérieure Département de génie électrique
Tworzenie modelu konceptualnego systemu informatycznego
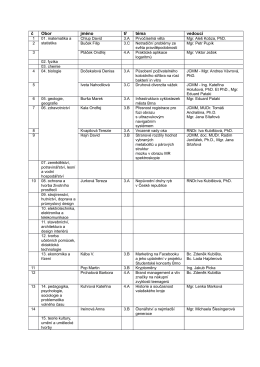
SOČ - práce postupující ze školního kola 2014
nové paradigma kognitivních věd?
Racionalismus a společnost
Výzkum vrcholně a pozdně středověké keramiky na území České
mpn 3 - Slovenský ústav technickej normalizácie
MEDSOFT 2012 - ODBORNÝ PROGRAM
betonarme köprülerin yapısal çelik elemanlar kullanılarak depreme
Jan Puc - SIF Praha
kesit hasar sınırlarının belirlenmesinde sargılama durumunun etkisi
Dopady konkurence politických uskupení na - IDEA - cerge-ei
DUBEN -ZÁŘÍ 2015 ZPRAVODAJ LOK-SČL