Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Rad
Műsorfüzet - Kodály Zoltán Magyar Kórusiskola
Zbornik radova
Elektromagnetni spektar
Upute za uporabu 499359
Скуп као основни математички појам
Baza podataka je uređeni skup međusobno po
bulanık doğrusal programlama modeli ile bir
Teorema Šreder-Bernštajn- seminarski rad
I-TASLAK DOGU.indd
null
ดาวน์โหลดเอกสารแนบ - กองบริหารการวิจัย มหาวิทยาลัยธรรมศาสตร์
Simplicijalni kompleksi kao kompleksni sistemi
Osnovni elementi fuzzy sistema zaključivanja
Dizajn fuzzy kontrolera - Vanr.prof.dr. Lejla Banjanović
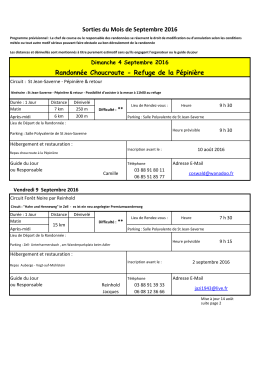
Toutes les sorties du mois de septembre 2016