Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
akcenatski rečnik srpskog jezika namenjen sintezi govora
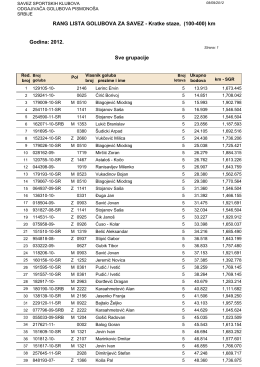
km Sve grupacije Godina: 2012.
ZAPYTANIE OFERTOWE - Urząd Gminy Zakrzówek
DTTV Headends SISTEM ZA DTTV DISTRIBUCIJU
Sayı 13: 31 Mart — 6 Nisan 2014
Dijaspora Feb 2008 - Bosnian Media Group
uN €1
02 Zabavna Gramatika 4
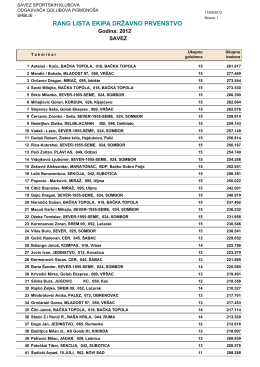
rang lista ekipa državno prvenstvo
Krumlov 2 - Deník.cz
Životopis
Upute za podnositelje DI obrasca