Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Seminarski rad - Tamara Đorđević
Full Text - Journal Of Business Research
intergalaktički bilten 1 - Foundation for the Law of Time
Bilgisayar Mühendisliği Bitirme Tezi Konuları
Laku noc klasicnoj sijalici (zarulji)
ELM3111 Digital Electronics and Microprocessors Mux Decoder
Semantik Web Arama Motoru Üzerine Bir İnceleme
Podmínky a pravidla pro použití uvítacího poukazu
skripta_1 - WordPress.com
SISTEMI PODRŠKE PRI DONOŠENJU ODLUKA
REVIZNÍ SYSTÉM VZP
Bir Durum Çalışması - CEUR
Informacija o ostvarenim rezultatima deminiranja i uništavanja
Spravodaj c 174 Svedectvo času - szcpv
Rozpis domácích utkání týmů z Premier League pro sezonu 2016
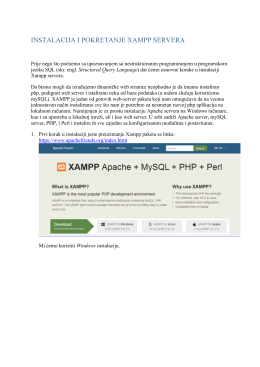
INSTALACIJA I POKRETANJE XAMPP SERVERA
Coagadex, human coagualtion factor X
Co jsou otevřená propojená data
GENÇLİK SPOR ve BARIŞ Bir 19 Mayıs Sabahı
Ontologie poza filozofią Studium metafilozoficzne
Drenažni sistemi u fazi gradnje objekata
9713/16 COR 1 az 1 DGE 1A Dokumentam ST 9713/16 INIT ir jābūt