Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Baze podataka 2 - Projektovanje informacionih sistema i Baze
Glava 5 PASIVNI FILTRI
Фотограметрија и даљинска детекција 2
Volume 3, Year 1, October 2011
SOLUN JuniorTravel d.o.o. Jagodina tel/fax. : + 381 (0
Opel Astra Sedan 1.6 CDX 19.000 TL İlan detayları
Tofaş Serçe 5.750 TL İlan detayları
Slayt 1 - Prof. Dr. Ahmet URSAVAŞ
Zadatak - poslovna informatika
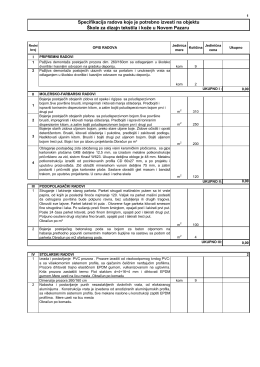
Predmer radova
Пројектовање софвера – Основни концепти Јаве
Metodika nastave računarstva B Primer kolokvijuma 2016
ADF Analogni filtri 2 Skripta
PDF dokument - Filip Travel
Bled,paket letovanje 2016. Big Blue
sorento - Turistička agencija Big Blue
Naziv treninga: Power Pivot za Excel
Pdf yap
download
HOTEL AQUA STAR DANUBE 4*- KLADOVO
baze podataka - Singipedia
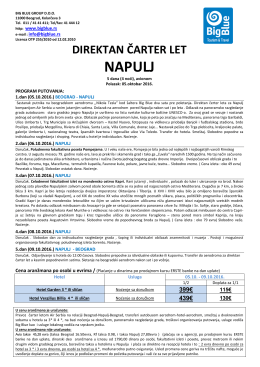
napulj - Turistička agencija Big Blue - Cenovnici
KARTA CHARAKTERYSTYKI